CSCRC SCReeD
A cybersecurity dataset sharing Platform.
SCReeD Platform Overview
SCReeD is a platform purposefully designed for sharing cybersecurity research data, including, but not limited to cybersecurity datasets generated by CSCRC research projects. For sharing cyber-datasets, general-purpose dataset sharing platforms are not ideal, and often not suitable, due to many reasons, such as the data sensitivity, volume, complexity, and wide range of file formats and serialisations typical to cybersecurity research datasets; also they can be authentic, synthetic, or hybrid, with different potential applications. In addition, a variety of audiences should be considered when sharing cybersecurity datasets, and all these require different levels of access, whether for CSCRC partners, Australian researchers, Australian industry practitioners, 5 Eyes researchers, the EU, or the world, which makes access control crucial in this application—compared to having only the option to share datasets with the general public, which is what many general-purpose/domain-independent dataset sharing platforms focus on.
The data captured in cybersecurity research datasets can be beneficial not only to the academic community, but also the industry in terms of adding new functionalities to, and test existing capabilities of, software tools; evaluating analytic performance of tools; assessing IT infrastructures’ vulnerability; identifying new types of cyberthreats, etc.
SCReeD defines standards for sharing cybersecurity datasets, provides guidelines for users so that the metadata to capture for cybersecurity datasets is streamlined, including technical and legal considerations, without the need for the uploader to be an expert in data sharing.
SCReeD Dataset Uploading Guidelines
The guidelines are provided for SCReeD users regarding dataset uploading, ensuring a systematic approach and inclusion of all relevant metadata.
Before Uploading
Before uploading, users need to do following steps.
- Be a member of CSCRC-SCREED organization on GitHub. (Please contact masooma.iftikhar@data61.csiro.au for membership.)
- Prepare the dataset(s) according to the SCReeD Dataset Preparation Guidelines (Click View Raw to download).
- Download and fill all relevant metadata in the SCReeD Dataset Declaration Form (Click View Raw to download).
- Also fill all relevant metadata in the online form before uploading.
(Note: Metadata for the uploaded datasets on SCReeD platform is available here)
The Uploading Process
Once you are done its time to upload the dataset. To upload the datasets, there are two methods, user can follow either of them.
Method 1:
To upload data with method 1, users need to do following steps:
- Go to CSCRC-SCREED and login.
- Click repositories on the top to create a GitHub repository to host your dataset.
-
Click on the + on the top right as shown below.
-
Create a folder to hold your data file, in this example, we will create a folder called dataset. Click on the Create new file button, and type in dataset/.githold. This will create a folder called dataset and place a file called** .githold** inside it.

- Upload your data file into this folder by clicking on button Upload files.
- Create a .dataherb folder in the root of your repository. Now the folder structure should be
. ├── README.md ├── .dataherb ├── dataset └── your_data_file - Create a file .gitattributes in the .dataherb folder with the following content:
*.docx binary *.pdf binary - Upload the prepared SCReeD Dataset Declaration Form in the .dataherb folder by clicking on the Add file button, and select upload files. Then ** drag and drop** the prepared SCReeD Dataset Declaration Form to upload in the .dataherb folder.
- Create a file metadata.yml in the .dataherb folder with the following content:
name: [Name of your dataset] description: [Describe your dataset here] contributors: name: [Name of the the first contributor] data: name: [name of your data file, optional] description: [description of your data file, optional] path: [path_to_your_data_file] format: [format of your data file] size: [size of your data file] fields: name: [name of the first colomn] description: [description of the first column] name: [name of the second colomn] description: [description of the second column] name: [name of your second data file, optional] description: [description of your second data file, optional] path: [path_to_your_data_file] format: [format of your data file] size: [size of your data file] fields: name: [name of the first colomn] description: [description of the first column] name: [name of the second colomn] description: [description of the second column] license: name: [Name of the license of the dataset] link: [Link to the license page] references: name: [Name of the first reference] link: [https://link_to_your_first_reference]This is for example, one could use similar or less content for metadata as required.
- Now the uploaded process is complete, and others can view your dataset repository.
- You and others can view your dataset repository as shown in the below example.
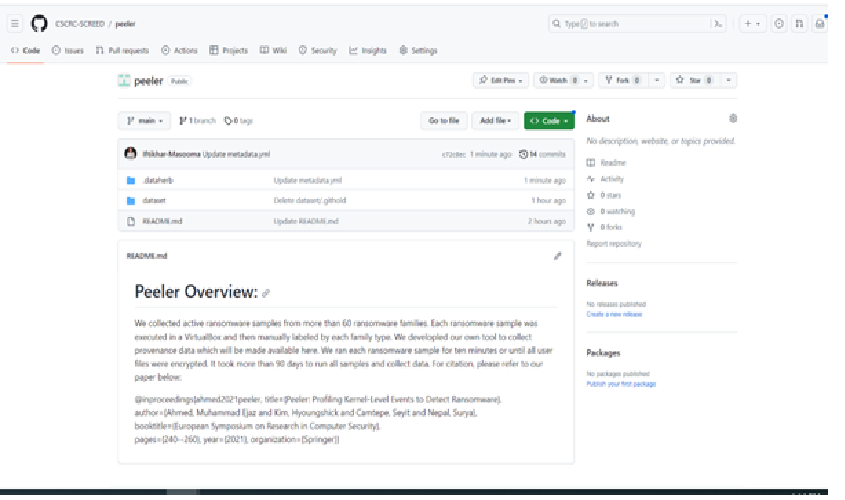
Method 2:
To upload data with method 2, users need to do following steps:
- Go to CSCRC-SCREED and login.
- Click repositories on the top and select the repository with name “Sample”.
- Then Click on the Code button, and select download ZIP as shown below. This will create a copy of the Sample repository on your local machine.

- UnZip the downloaded Sample repository folder and do the following steps.
- Open .dataherb folder and edit metadata.yml accordingly. Also add prepared SCReeD Dataset Declaration Form in it.
- Add your datasets files in the dataset folder and update ReadMe file about the dataset accordingly.
- Now go back to CSCRC-SCREED. Select repositories tab on top and click on the + on the top right to create a GitHub repository to host yor dataset as shown below.
- Create dataset and .dataherb folders. For each folder, click on the Create new file button, and type in dataset/.githold for dataset folder and .dataherb/.githold for .dataherb folder, respectively. This will create two folders called dataset and .dataherb with a file called** .githold** inside it.
- Now the folder structure should be
. ├── README.md ├── .dataherb ├── dataset - Open the downloaded Sample repository folder saved in your local machine and from this upload all files in the respective folders craeted on GitHub, for example, click dataset folder on GitHub and click on the Add file button, and select upload files. Then ** drag and drop** all the required files from the dataset folder in your local machine. Repeat this for .dataherb folder.
- In the end update README.md for the created repository and add details about the repository.
- Now the uploaded process is complete, and others can view your dataset repository.